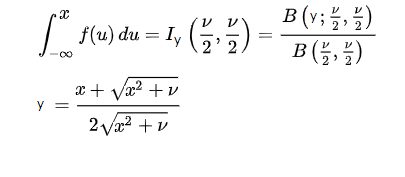 左の計算式は、下側の累積確率を求めるものです。
左の計算式は、下側の累積確率を求めるものです。正則ベーター関数を利用して計算されます。
t分布
母集団の平均と分散が判らず、標本サイズが小さい場合に平均を推定するのに使用されます。
詳細は、ウィキペディア t分布を参照して下さい。
重要な分布の一つとなっているので、t分布で、検索すれば説明が沢山みつかります。
左の計算式は、下側の累積確率を求めるものです。
正則ベーター関数を利用して計算されます。
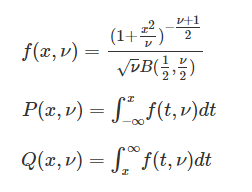
f(x,v)は、確率密度、P(x,v)は下側累積確率、Q(x,v)は上側累積確率を表しています。
全体の累積確率は1なので下側累積確率が計算出来れば、上側累積確率を計算出来ます。
プログラムの確率密度は、ウィキペディアにある関数式で計算しています。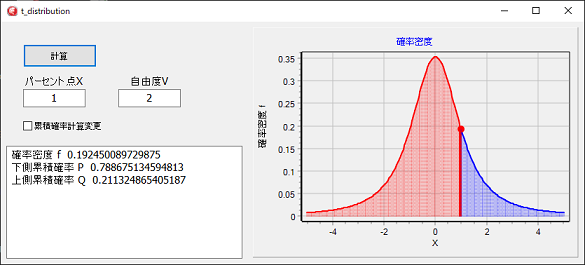
プログラム
プログラムは、C言語辞典 アルゴリズムにあるt分布をDlphi用に変換したものに、確率密度の計算とグラフを追加しています。
累積確率の計算は、二つ用意して、同じ答えが出ることにより検算しています。
unit Main;
interface
uses
Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, System.Classes, Vcl.Graphics,
Vcl.Controls, Vcl.Forms, Vcl.Dialogs, VclTee.TeeGDIPlus, Vcl.StdCtrls, Vcl.ExtCtrls,
VCLTee.Series, VCLTee.TeEngine, VCLTee.TeeProcs, VCLTee.Chart, system.UITypes, system.Math;
type
TForm1 = class(TForm)
Chart1: TChart;
Memo1: TMemo;
LabeledEdit1: TLabeledEdit;
Button1: TButton;
LabeledEdit2: TLabeledEdit;
Series1: TLineSeries;
Series2: TLineSeries;
Series3: TPointSeries;
CheckBox1: TCheckBox;
Series4: TLineSeries;
procedure Button1Click(Sender: TObject);
private
{ Private 宣言 }
public
{ Public 宣言 }
end;
var
Form1: TForm1;
implementation
{$R *.dfm}
// ************ loggamma(x) ************
const
//ベルヌーイ数B(2)、B(4)、B(6)、...、B(16)
B : array[1..8] of double = ( 1.0 / 6, // B(2)
-1.0 / 30,
1.0 / 42,
-1.0 / 30,
5.0 / 66,
-691.0 / 2730,
7.0 / 6,
-3617.0 / 510); // B(16)
m: integer = sizeof(B) div sizeof(double);
function loggamma(x: double): double; // ログガンマ関数
var
i : integer;
sum : double;
xx, v : double;
xj : double;
lng : double;
ln_sqrt_2pi: double;
begin
ln_sqrt_2pi := ln(sqrt(2 * pi)); // = ln(2 * pi) / 2;
sum := 0;
v := 1;
while x < m do begin
v := v * x;
x := x + 1;
end;
xx := x * x;
xj := x;
lng := ln_sqrt_2pi - x + (x - 0.5) * ln(x) - ln(v);
for i := 1 to m do begin
sum := sum + B[i] / (i * 2 * (2 * i - 1)) / xj;
xj := xj * xx;
end;
result := sum + lng;
end;
//**********************************************************
function p_beta(x, a, b : double): double;
var
k : integer;
p1, q1, p2, q2, d, previous : double;
begin
if a <= 0 then begin
result := MaxDouble;
exit;
end;
if b <= 0 then begin
if x < 1 then begin
result := 0;
exit;
end;
if x = 1 then begin
result := 1;
exit;
end;
result := MaxDouble;
exit;
end;
if x > (a + 1) / (a + b + 2) then begin
result := 1 - p_beta(1 - x, b, a);
exit;
end;
if x <= 0 then begin
result := 0;
exit;
end;
p1 := 0;
q1 := 1;
p2 := exp(a * ln(x) + b * ln(1 - x)
+ loggamma(a + b) - loggamma(a) - loggamma(b)) / a;
q2 := 1;
k := 0;
while k < 200 do begin
previous := p2;
d := - (a + k) * (a + b + k) * x
/ ((a + 2 * k) * (a + 2 * k + 1));
p1 := p1 * d + p2;
q1 := q1 * d + q2;
inc(k);
d := k * (b - k) * x / ((a + 2 * k - 1) * (a + 2 * k));
p2 := p2 * d + p1;
q2 := q2 * d + q1;
if q2 = 0 then begin
p2 := Maxdouble;
continue;
end;
p1 := p1 / q2;
q1 := q1 / q2;
p2 := p2 / q2;
q2 := 1;
if p2 = previous then begin
result := p2;
exit;
end;
end;
Form1.Memo1.Lines.Add('p_beta: 収束しません');
result := p2;
end;
function q_beta(x, a, b: double): double;
begin
result := 1 - p_beta(x, a, b);
end;
//**********************************************************
function p_t(t : double; df: integer): double; // t 分布の下側確率
begin
result := 0.5 * p_beta(df / (df + t * t), 0.5 * df, 0.5);
if t >= 0 then
result := 1 - result;
end;
{
function P_t(x: double; df: integer): double;
var
y: double;
begin
y := (x + sqrt(x * x + df)) / (2 * sqrt(x * x + df));
result := p_beta(y, df/ 2, df / 2);
end;
}
function q_t(t : double; df: integer): double; // t 分布の上側確率
begin
result := 0.5 * p_beta(df / (df + t * t), 0.5 * df, 0.5);
if t < 0 then result := 1 - result;
end;
//**********************************************************
function tf(t: double; df : integer): double; // 確率密度
var
p1, p2, p3 : double;
begin
p1 := exp(loggamma((df + 1) / 2));
p2 := exp(loggamma((df) / 2)) * sqrt(df * pi);
p3 := power(1 + t * t / df, -(df + 1) / 2);
result := p1 / p2 * p3;
end;
//**********************************************************
function p_t2(t: double; df: integer): double; // t分布の下側累積確率
var
i : integer;
c2, p, s : double;
begin
c2 := df / (df + t * t); // cos^2
s := sqrt(1 - c2); // sin
if t < 0 then s := -s;
p := 0;
i := df mod 2 + 2;
while i <= df do begin
p := p + s;
s := s * (i - 1) * c2 / i;
inc(i, 2);
end;
if (df and 1) <> 0 then // 自由度が奇数
result := 0.5 + (p * sqrt(c2) + arctan(t / sqrt(df))) / PI
else // 自由度が偶数
result := (1 + p) / 2;
end;
function q_t2(t: double; df: integer): double; // t分布の上側累積確率
begin
result := 1 - p_t2(t, df);
end;
//**********************************************************/
procedure TForm1.Button1Click(Sender: TObject);
var
ch : integer;
x, xi : double;
Po, Qo : double;
fo: double;
df : integer;
dx : double;
min, max: double;
I: Integer;
GF : boolean;
begin
val(LabeledEdit1.Text, x, Ch);
if ch <> 0 then begin
MessageDlg('x値に間違いがあります。', mtInformation, [mbOk], 0, mbOk);
exit;
end;
val(LabeledEdit2.Text, df, Ch);
if ch <> 0 then begin
MessageDlg('V値に間違いがあります。', mtInformation, [mbOk], 0, mbOk);
exit;
end;
if df < 0 then begin
MessageDlg('Vの値がゼロ以下です。', mtInformation, [mbOk], 0, mbOk);
exit;
end;
Memo1.Clear;
fo := tf(x, df);
Memo1.Lines.Add('確率密度 f ' + floatTostr(fo));
if checkBox1.Checked = false then begin
Po := p_t(x, df);
Qo := q_t(x, df);
end
else begin
Po := p_t2(x, df);
Qo := q_t2(x, df);
end;
Memo1.Lines.Add('下側累積確率 P ' + floatTostr(Po));
Memo1.Lines.Add('上側累積確率 Q ' + floatTostr(Qo));
Series1.Clear;
Series2.Clear;
Series3.Clear;
Series4.Clear;
Series3.AddXY(x, fo);
min := -5;
max := 5;
if x <= min + 0.5 then min := x - 1;
if x >= max - 0.5 then max := x + 1;
dx := (max - min) / 200;
Gf := False;
for I := 0 to 200 do begin
xi := I * dx + min;
fo := tf(xi, df);
if xi <= x then begin
Series1.AddXY(xi, fo);
Series4.AddXY(xi, 0,'', clRed);
Series4.AddXY(xi, fo,'', clRed);
Series4.AddXY(xi, 0,'', clRed);
end
else begin
if Gf = False then begin
Series1.AddXY(xi - dx, 0);
Series1.AddXY(xi, 0);
Series1.AddXY(xi, fo);
Gf := True;
end;
Series2.AddXY(xi, fo);
Series4.AddXY(xi, 0,'', clblue);
Series4.AddXY(xi, fo,'', clblue);
Series4.AddXY(xi, 0,'', clblue);
end;
end;
end;
end.
![]() Students_t_distribution.zip
Students_t_distribution.zip